Method
Pipeline Overview
Our pipeline takes an image and a text prompt about target objects, producing instance masks with open-vocabulary category labels. The SD and CLIP models are frozen; only the specialised modules are trained.
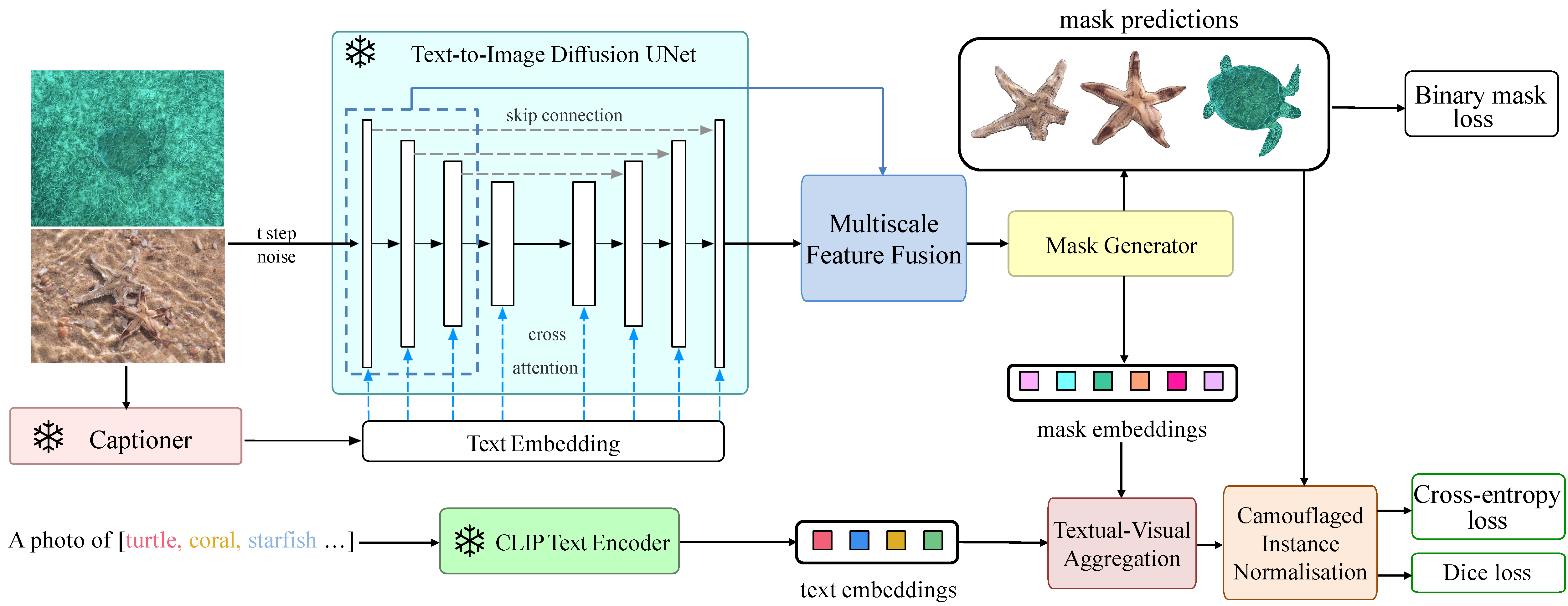
Multi-scale Features Fusion
Fuses multi-scale features from the SD encoder with the final decoder layer via 1×1 convolution, element-wise multiplication, and residual addition. Captures both fine-grained and broad contextual information critical for detecting objects at varying scales.
Textual-Visual Aggregation
Computes instance-aware cross-modal interactions between mask embeddings and CLIP text embeddings. Uses softmax-weighted dot product with mean-normalisation to remove background noise and focus features on text-specified foreground objects.
Camouflaged Instance Normalisation
Inspired by adaptive instance normalisation, CIN applies learnable affine transformations to textual-visual features conditioned on instance masks, producing final refined masks. Uses a confidence score rather than a class score for category-agnostic instance existence.

